
{kind=link}
Machine learning har for alvor gjort sit indtog i den moderne digitale annoncørs værktøjskasse. Især har muligheden for at skabe look-a-like audiences (også kaldet similar audiences, tvillinger m.m.) de seneste år vist sig som et ekstremt effektivt værktøj for mange annoncører. Mange annoncører benytter allerede nu look-a-like modellering for at højne kvaliteten af deres digitale marketingindsats i målretningen mod relevante prospects. Men det ses desværre ofte, at annoncører ikke lykkes med at få ordentlig performance ud af deres look-a-like model. Læs videre her, hvis du vil vide teorien bag, hvordan en look-a-like model fungerer, og hvordan du får succes med at bygge effektive look-a-like audiences, som markant kan forbedre effektiviteten af dit prospecting spor og din digitale marketingindsats.
Hvad er en look-a-like model?
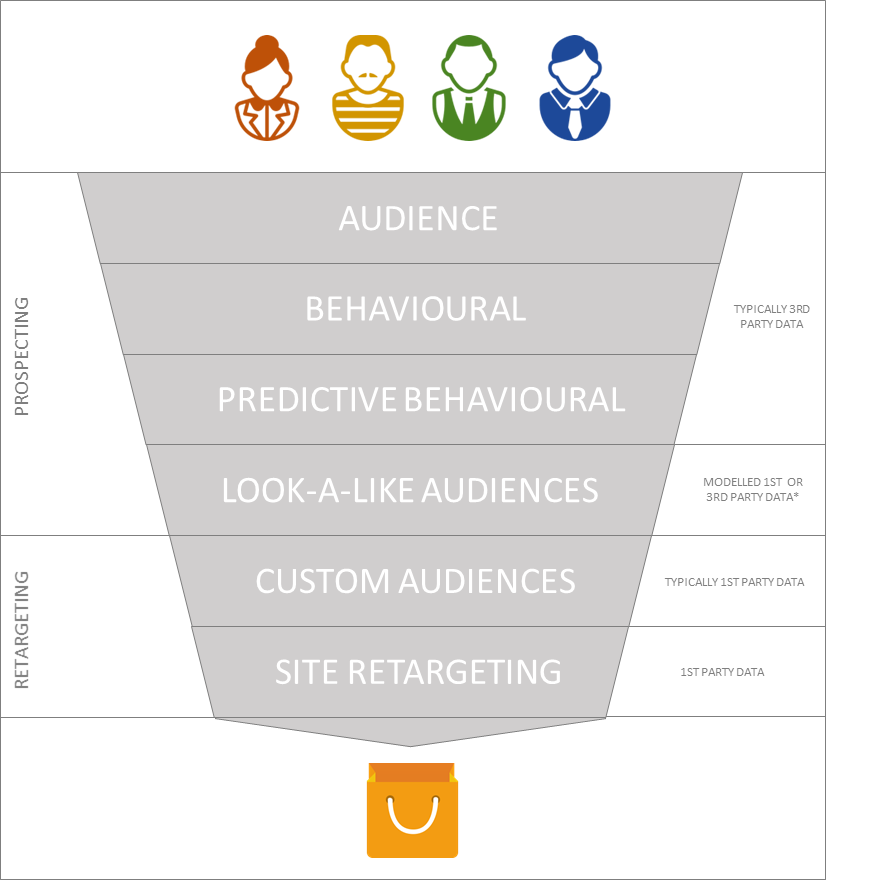
En look-a-like model er meget kort fortalt et sæt af data, der typisk er modelleret på baggrund af en annoncørs egen data, også kaldet et data seed (eksempelvis e-mails, app-data mv.), et sample audience opsamlet gennem en ’learning pixel’ på et website eller 3. parts data købt hos en datavendor. Datamodellen benyttes typisk til at identificere prospects, der har lignende adfærd, som de personer i det datasæt man har fodret modellen med. Denne data kan skaleres imellem forholdene mellem præcisionen på modellen vs. rækkevidden på modellen.
Eksempel:
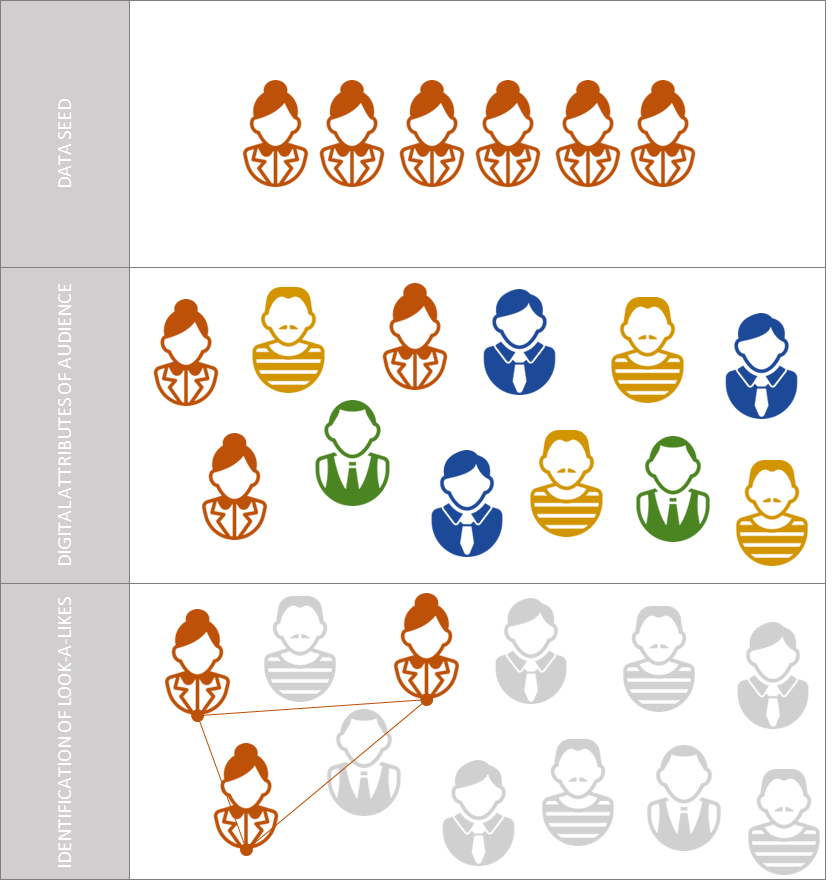
En e-mail-liste med kunder i en specifik produktgruppe uploades til eksempelvis Googles eller Facebooks platform. Systemet analyserer de digitale attributer og signaler, som dette data seed indeholder (eksempelvis geografisk data, demografisk data, interesse data, adfærdsdata med videre). Når systemet har klassificeret dette data seed måles dets egenskaber op i mod et større audience, eksempelvis alle mennesker i Danmark. Ud fra dette identificeres brugere, som har lignende karakteristika og adfærd som data seeded og disse samles i et segment.
Skal jeg altid bruge look-a-like audiences i min prospecting strategi?
Look-a-like audiences kan være ekstremt stærke til at forbedre effekten af annoncørers prospecting setup og fungerer enormt godt på både bløde såvel som hårde KPI’er. Selvom vi mennesker udadtil virker meget forskellige, er vi meget mere ens, end vi lige går og tror. Vi afgiver mange digitale signaler, som fungerer som stærke indikatorer på vores adfærd og i særdeleshed giver stærke signaler om nuværende og kommende forbrugsmønstre. Du kan derfor med fordel næsten altid lave look-a-like audiences, og giver du din look-a-like model det helt rigtige data seed til at bygge modellen ud fra, kan man i visse tilfælde opleve performance, som er mere effektivt end både custom audiences og site-retargeting. For at besvare ovenstående spørgsmål er en look-a-like model kun så stærk, som det data seed du giver den. Derfor er det vigtigt, at den data som du bygger din model efter har ’digitalt signal’, som gør at dit audience er unikt fra den brede befolkning eller mere generiske demografiske målgrupper.
Eksempel:
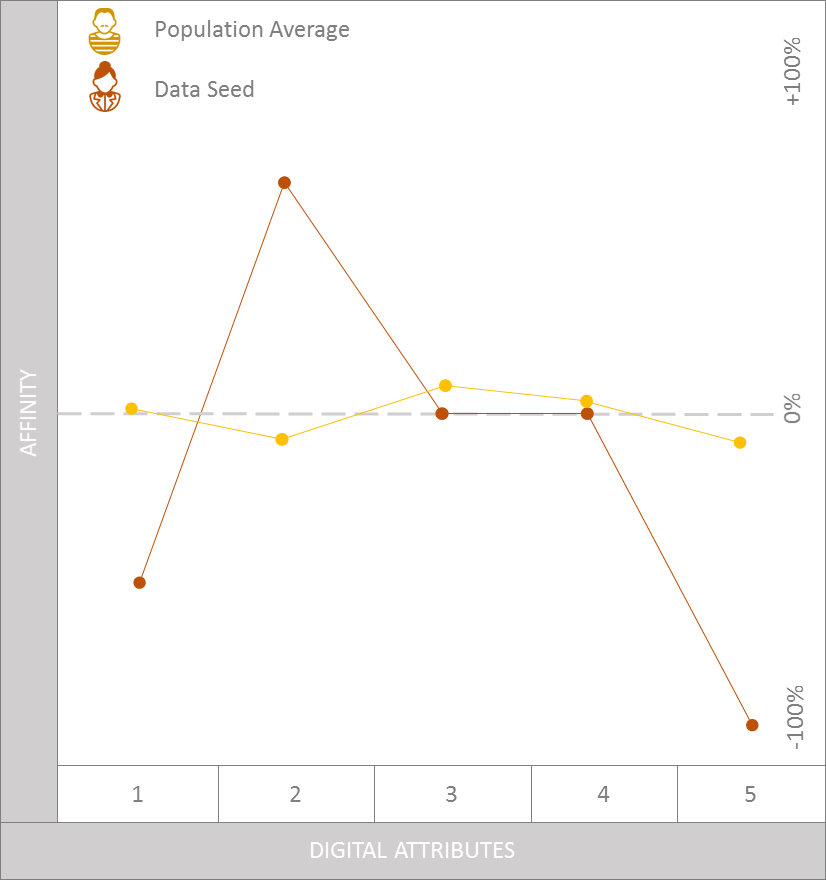
Nedenfor ses et visualiseret eksempel på, hvordan et data seed optimalt set bør adskille sig fra den brede befolkning, og dermed sikre at data seeded har tilstrækkeligt stærkt digitalt signal. De digitale attributer vist i modellen kan være adfærd, interesser, eller andre indikatorer som disse brugere har udvist høj eller lav affinitet i forhold til gennem deres digitale adfærd. Data seedet kan eksempelvis være eksisterende kunder, der har købt eller vist interesse for et specifikt produkt på annoncørens website. Visualiseringen viser blot, at data seedet skiller sig ud på væsentlige parametre fra den brede befolkning (population average), og at der dermed et tilstrækkeligt digitalt signal til at modellen formodes at måtte være effektiv.
Test dit Data Seed
I visse DMP’er har man muligheden for at teste styrken af sin look-a-like model, inden man aktiverer den. Dette kan være et super effektivt redskab til på forhånd at give dig en stærk indikation af, hvorvidt dit look-a-like audience skiller sig ud fra den brede befolkning og dermed kommer til at være effektivt i at lokalisere og målrette de mest højpotentielle prospects. I GroupM-regi tester vi styrken på vores datamodeller gennem en såkaldt ’Gains Chart’. En Gains Chart viser forholdet mellem den estimerede rækkevidde på din look-a-like model og performance løft, som det data seed du har bygget din model på forventes at give. En god model ser ud som nedenstående visualisering (Gains Chart 1). Her kan det ses, at graferne for reach og performance løft er omvendt korrelerende og følger hinanden simultant i denne datavisualisering.
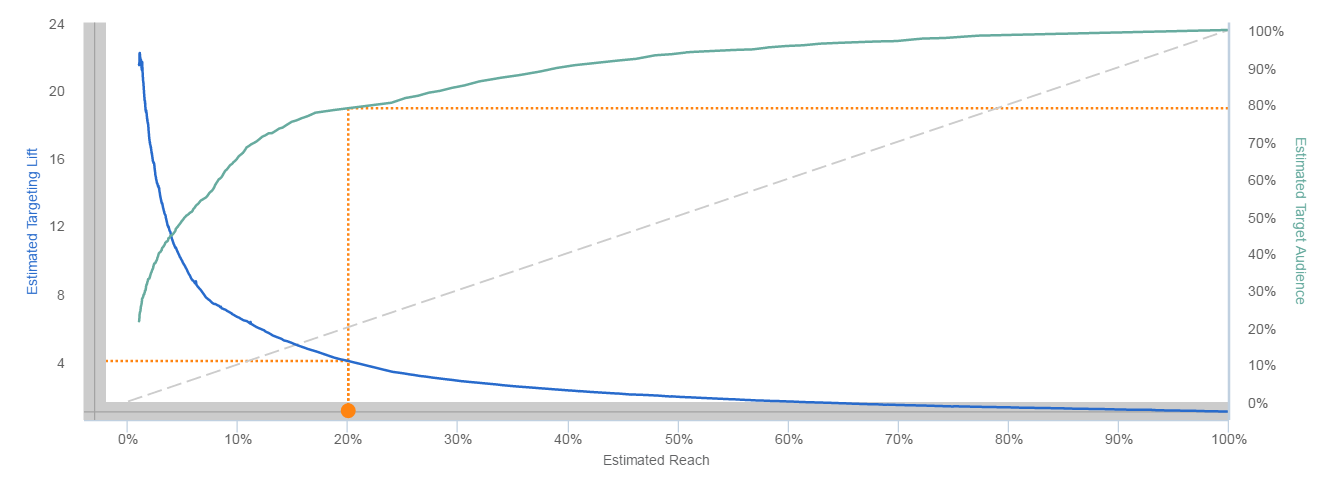
Gains Chart 1
En mindre stærk model kan derimod se ud som nedenstående visualisering, hvor man kan se at det forventede performance løft (visualiseret ved skalaen på y-aksen og den blå linje) er markant mindre en ved Gains Chart 1. Samtidig ses det, at linjen for det forecastede løft i performance er ujævn, hvilket også indikerer i styrken i det valgte data seed er lav.
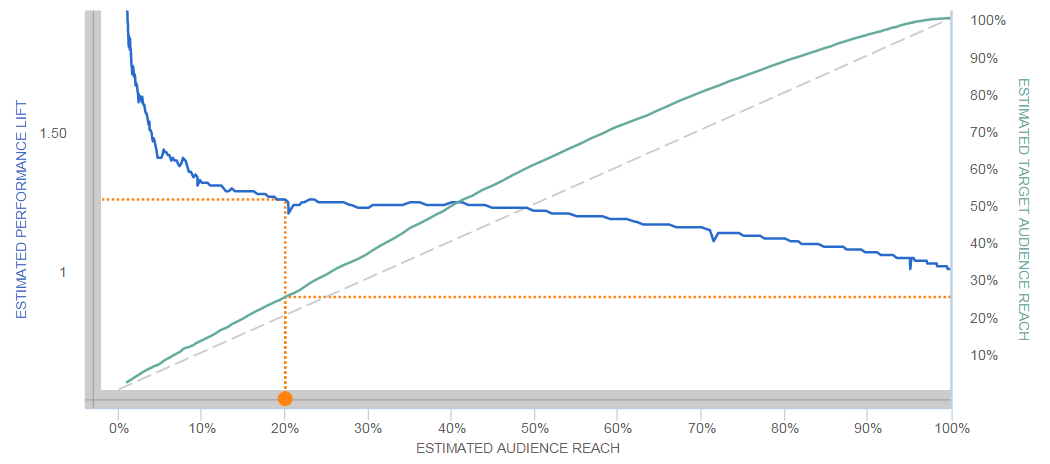
Gains Chart 2
Men hvordan ved du om det data seed du har tænkt dig at bruge i din look-a-like model har tilstrækkeligt digitalt signal som gør, at dit audience bliver stærkt og kommer til at levere god performance, hvis ikke du har muligheden for at teste det via et Gains Chart?
Jeg har opstillet nedenstående eksempel i forhold til et datahiearki med udgangspunkt i en tilfældig annoncørs hjemmeside. Her ses hvad du bør være opmærksom på i din tagging af dit site, de audiences du opsamler, og den måde du aktiverer dataen på.
Front Page:
På forsiden af de fleste større annoncørers website er der typisk en meget broget skare af brugere, der typisk sender en bred vifte af digitale signaler. Netop på baggrund af dette kan det være svært at benytte forsiden til at modellere et look-a-like audience, da modellerne vil have sværere ved at finde de ligheder i brugernes digitale adfærdsmønstre, som modellen skal bruge for at identificere lignende brugere. Derfor er anbefalingen typisk, at medmindre dit site huser en meget unik brugerskare, som i høj grad sender de samme klare digitale signaler, er data fra forsiden typisk ikke det bedste data seed at bygge din model ud fra.
Sub category (Specifikke produkt-sider):
Har du i stedet en række undersider eller specifikke produktsider, som i højere grad opdeler brugerne fra forsiden, vil modellen typisk blive stærkere, når du benytter data seed fra denne type sider. Årsagerne er relativt enkel i og med, at de annoncører typisk har segmenteret produktportefølje, hvor den produkt specifikke kunderejse og de digitale signaler, der sendes i forbindelse med denne, kan være meget forskellige.
High potential behavior (Pre-purchase indicators):
Under hvert subsite/produktsite har du måske identificeret en række adfærdsmæssige indikatorer, som du ved er et skridt i købsrejsen mod den endelige konvertering. Det giver derfor god mening at få tagget disse op og bygget audiences fra brugere, der kraftigt indikerer, at de er på vej mod købet. Ved at benytte disse digitale indikatorer som dit data seed kan brugere med lignende adfærd identificeres og udvide din pool af højpotentielle prospects, som er tæt på at opfylde dine mest forretningskritiske KPI’er.
Eksempler på punkter som udviser stærke digitale signaler i en købsrejse:
1) Soft lead – sign up til nyhedsbrev, rabatkupon eller lignende
2) Brochure download – brugere der har kigget på mere
3) Browsing adfærd – længerevarende visits, pageviews og genbesøg
4) Varer i kurven – brugere der har lagt et produkt i kurven (kun e-commerce)
Actual converters (opdelt på produkt eller produktgruppe niveau):
Det vigtigste for dig som annoncør er naturligvis, at du målretter de prospects, som på et eller andet tidspunkt bliver købsmodne og lægger penge i butikken. Det lyder umiddelbart som en let øvelse bare at bygge et audience på alle, der har konverteret og aktivere dette. Men det er netop denne fejl som mange begår. De tager den samlede pulje af alle, der har konverteret på tværs af produkter og produktgrupper. Forestil dig at du er i billedkunstlokalet i folkeskolen og skal blande farver, og du blander alle de farver, du har på hele paletten. Det der kommer til at ske er, at du ender op med en grå-brun utilfredestillende masse, som ikke blev det prangede farvestrålende resultat, du havde forestillet dig oppe i hovedet.
Derfor er det helt centralt, at du får tagget dit site op på produkt- og produktgruppe niveau, samtidig med at du i dit CRM system let kan isolere e-mails på kunder i en specifikproduktgruppe og benytte disse som dit data seed i din look-a-like model.

Hvor stort et data seed kræver det før jeg kan lave look-a-like modeller?
Det er meget forskelligt fra platform til platform, hvor meget data det kræves for at lave en stærk look-a-like model. Du kan i Facebooks og Googles univers selv vælge, om du vælger at bygge dit audience på data opsamlet via en audience pixel (learning tag) på dit site eller uploade CRM data i disse systemer og modellere på baggrund af denne data.
Google: Similar audiences – modelleres på et data seed af minimum 5.000 cookies – eller minimum 1.000 identificerede e-mails.
Facebook: Look-a-like audiences – modelleres på et data seed helt ned til minimum 100 brugere – Facebook anbefaler dog selv en seed size på mellem 1.000 og 50.000 brugere.
[m]insights DMP – kan modelleres på to forskellige seed størrelser:
- Standard seed – modelleres på et data seed af minimum 2.000 cookies inden for de sidste 30 dage.
- Lower seed – modelleres på minimum 50 cookies indenfor de sidste 30 dage.
Skalering af dit look-a-like audience
I både Facebook og i diverse DMP’er (eksempelvis [m]insights eller Adform) har du i din målretning mulighed for at skalere din model (visualiseret i Gains Chart 1 længere oppe). Dette betyder i princippet, at du laver et trade-off imellem præcisionen på din model og den rækkevidde af brugere, du rammer med din målretning. Der kan være meget at hente ved at skrue på denne kombination, og det anbefales altid at man tester flere forskellige modeller af i forhold til præcision vs. rækkevidde tradeoff’et. På visse annoncører performer de helt snævre modeller særdeles effektivt, hvor en opskalering af rækkevidden på audiencet vil have et negativt impact på performance, mens andre typer af annoncører sagtens kan fungere godt med en bredere skalering af deres look-a-like audience.
Opsummering – gode råd
Afslutningsvist vil jeg lige opsummere de learnings der igennem dette efterhånden lange blogindlæg er blevet opsamlet:
1) Byg dit audience på baggrund af data med et signifikant digitalt signal – ikke bare besøgende på forsiden.
2) Hav styr på din pixel-tagging og CRM datastruktur, så du indkapsler de mest brugbare data seeds.
3) Start med at lav look-a-likes på de brugere, der har udvist digital adfærd tættest på dine forretningsmæssige målsætninger og arbejd dig sidenhen længere tilbage i den digitale købsrejse.
4) Test styrken på din look-a-like model (Se gains chart 1 og 2)
5) Eksperimentér! – Der er ingen endegyldige sandheder på tværs af brancher, typer af annoncører, sites med videre. Det hele handler om at teste forskellige skaleringer, dataopsamlingspunkter og løbende bliver klogere.
6) Giv kontinuerligt din model ny data. Din datamodel er kun så stærk, som det data seed du giver den. Derfor skal du løbende igennem både Always On, men også mere kortvarige kampagneaktiviteter fodre din model med den seneste data for at sikre, at dit audience har de bedst mulige præmisser for at performe.
Overholder du ovenstående retningslinjer, har du givet dig selv de optimale betingelser for at bygge et stærkt look-a-like audience, og markant forbedre effekten af din digitale marketingindsats mod nye og højrelevante prospects.